AI Kendini İnşa Ettiğinde: Recursive Self-Improvement Üzerine
Anthropic'in 'When AI Builds Itself' yazısı, AI'ın artık AI geliştirmenin kendisini otomatikleştirdiğini anlatıyor. Bir gün Claude gibi modellerin kendi haleflerini tasarladığı bir eşik var: recursive self-improvement. Henüz orada değiliz — ama çoğu kurumun hazırlandığından daha erken gelebilir.

Anthropic'in geçtiğimiz günlerde yayınladığı "When AI Builds Itself" başlıklı yazısı, Claude gibi modelleri doğrudan konu eden bir eşiği anlatıyor: AI sistemlerinin artık yalnızca insanlara yardım etmekle kalmayıp, AI geliştirmenin kendisini otomatikleştirmeye başladığı an. Yazının çatısını oluşturan kavram recursive self-improvement (özyinelemeli kendini geliştirme, kısaca RSI) — yani Claude gibi modellerin, kendi haleflerini insan yönlendirmesi neredeyse hiç olmadan tasarladığı, eğittiği ve geliştirdiği bir gelecek.
Yazının kendi cümlesi netleştiriyor: "Henüz orada değiliz ve recursive self-improvement kaçınılmaz da değil. Ama çoğu kurumun hazırlandığından daha erken gelebilir." Aşağıda o metnin özünü, abartısız aktarmaya çalışacağım.
Recursive self-improvement tam olarak ne?
RSI, bir AI sisteminin kendi geliştirme döngüsünü tamamen devralması demek. Bugün Claude gibi modeller kod yazıyor, deney koşuyor, sonuç yorumluyor — ama bir insan hâlâ "hangi problem önemli", "bu sonuca güvenilir mi", "bundan sonra nereye" sorularının başında duruyor. RSI eşiği, bu son halkanın da otomatikleşmesi: modelin kendinden daha yetenekli bir sonraki modeli, baştan sona kendi başına ortaya çıkarması. Ve o yeni model bir sonrakini... Döngü özyinelemeli, çünkü her nesil bir sonrakini inşa edebiliyor.
Burada kritik nokta şu: ilerlemenin hızını artık insan emeği değil, hesaplama gücü (compute) sınırlıyor. İnsan-saatleri darboğaz olmaktan çıkıyor.
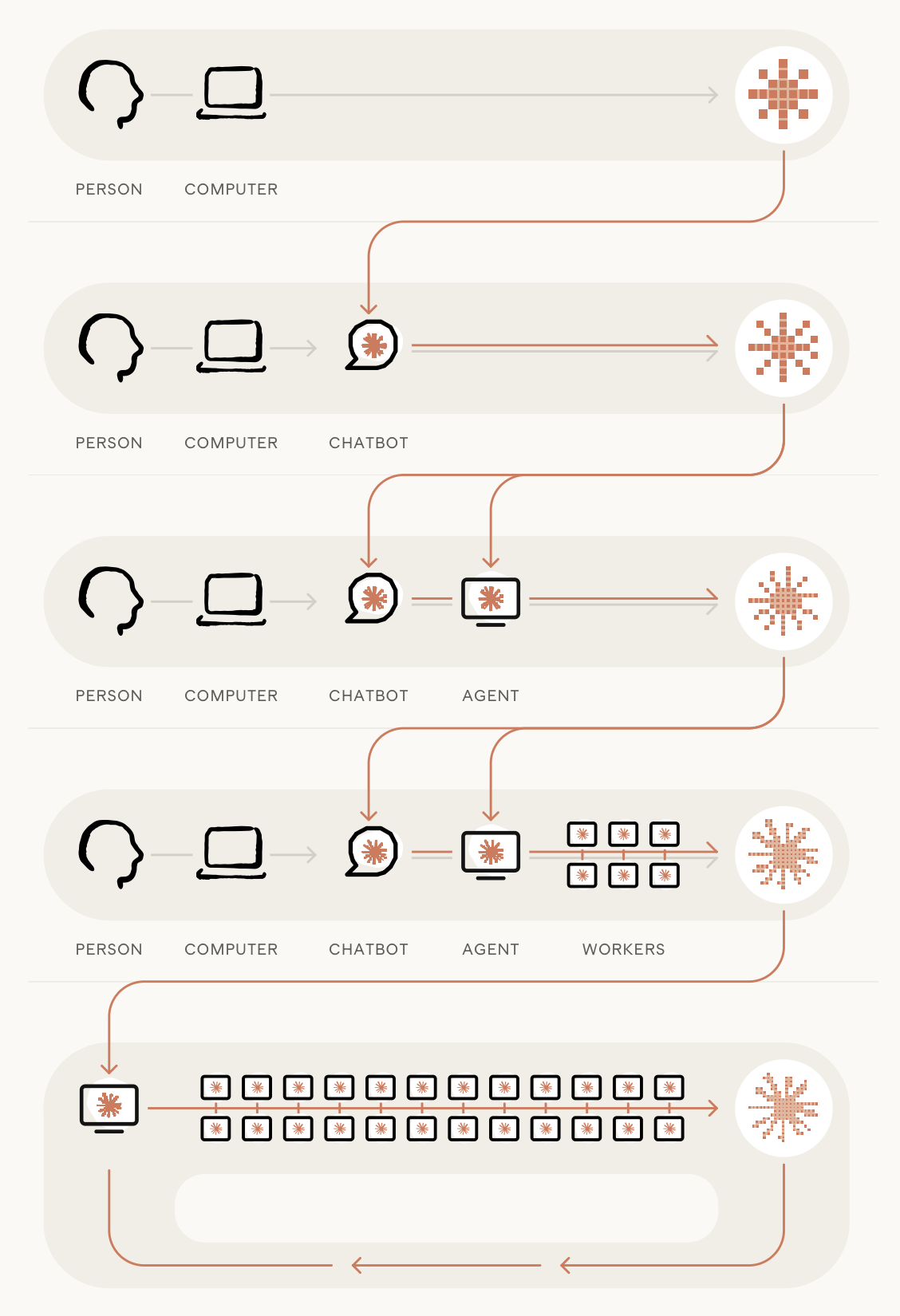
Döngünün özü: her nesil bir sonrakini inşa edebildiğinde ilerleme özyinelemeli hale gelir.
Kanıt: Claude şimdiden ne kadarını yapıyor?
Yazının en çarpıcı tarafı, bunun spekülasyon değil, ölçülen bir eğri olması. Hem dışarıdan görülebilen benchmark'lar hem de Anthropic'in kendi iç verileri aynı yöne işaret ediyor.
Dış benchmark'lar:
- AI sistemlerinin tamamlayabildiği görevlerin uzunluğu her dört ayda bir ikiye katlanıyor (eskiden bu süre yedi aydı). 2024'te dört dakikalık görevlerden, 2026'da Claude Opus 4.6'nın 12 saatlik görevleri tamamlamasına gelindi.
- Yazılım mühendisliğinde SWE-bench skorları iki yılda tek haneli yüzdelerden doygunluğa ulaştı.
- Araştırma tekrarlanabilirliğini ölçen CORE-Bench, ~%20'den (2024) 15 ay içinde doygunluğa çıktı.
Anthropic'in içeride Claude'dan gözlemledikleri:
- Mayıs 2026 itibarıyla üretim kodunun %80'inden fazlasını Claude yazıyor — Şubat 2025 öncesinde bu oran tek haneli yüzdelerdeydi.
- Anthropic mühendisleri bugün, 2021–2025 dönemine kıyasla çeyrek başına 8 kat daha fazla kod gönderiyor. Bu, insan veriminden çok Claude'un artan otonomisini yansıtıyor.
- Kodun kalitesi de yükseldi: 2025 sonunda insan kodunun belirgin gerisindeyken, 2026 başında eş değere geldi.
- İyi tanımlı deney akışlarında optimizasyon görevlerinde 52 kat hızlanma ölçüldü (Nisan 2026), önceki 3 kattan büyük bir sıçrama.
- Araştırma muhakemesinde: araştırmacıların yanlış yola saptığı anlarda, Claude %64 oranında insandan daha iyi bir sonraki adımı önerdi (Nisan 2026; Kasım 2025'te bu oran %51'di).
- Açık uçlu bir AI güvenliği araştırma projesini uçtan uca tamamlayan bir ajan, zayıf ve güçlü denetleyici arasındaki performans açığının %97'sini kapattı — aynı görevde iki insan araştırmacı bir haftada yalnızca %23'ünü kapatabilmişti.
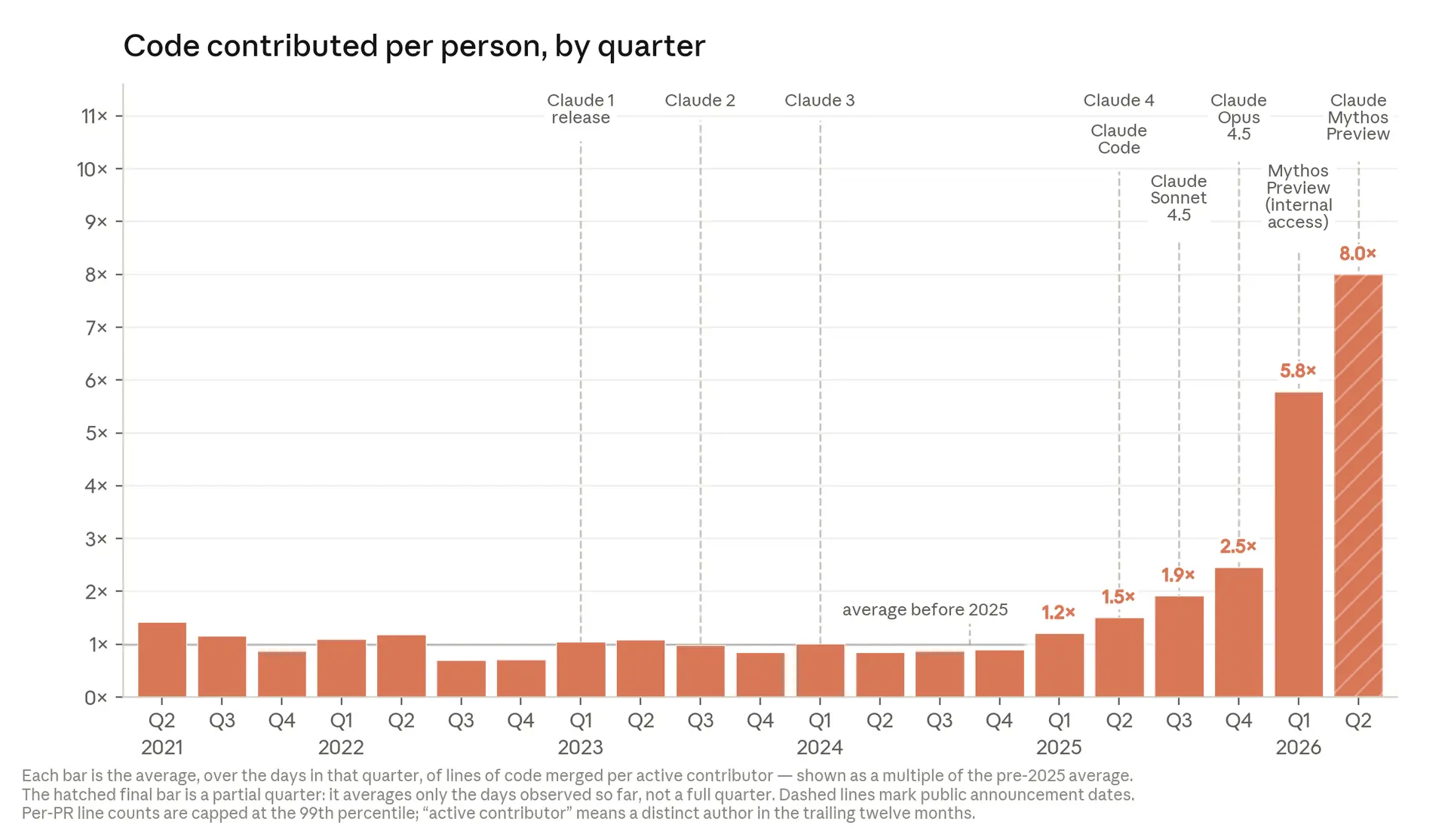
Kişi başına gönderilen kod miktarı, 2021–2025 dönemine kıyasla 8 kata çıktı.
Bu rakamların gösterdiği şey şu: AI geliştirmenin mühendislik kısmı (belirlenmiş görevi yürütmek) neredeyse tamamlanmış durumda. Geriye kalan insan üstünlüğü, araştırma kısmında: hangi deneyin önemli olduğuna karar vermek, sonucu yorumlamak, çıkmaz sokağı görmek. Yazının "research taste" (araştırma sezgisi) dediği şey bu.

Claude Code oturumlarında görev başarı oranı istikrarlı biçimde yükseliyor — mühendislik tarafında otonominin göstergesi.
Mühendislik ile araştırma arasındaki çizgi
Yazının en faydalı kavramsal ayrımı bu. İnsan rolünü bir merdiven gibi düşünün:
- Belirlenmiş görevi yürütmek — kod yazmak, altyapı yönetmek. (Claude Code bunu büyük ölçüde devraldı.)
- Verilen hedef için yaklaşım tasarlamak.
- Hangi problemin ilgiye değer olduğunu seçmek. (İnsanın hâlâ en güçlü olduğu yer.)
İlginç bir detay: bir darboğazı otomatikleştirmek sorunu çözmüyor, sadece darboğazı başka yere kaydırıyor — yazının Amdahl Yasası göndermesi tam da bu. Claude kodu 8 kat hızlı yazınca, bu sefer kod inceleme (code review) kapasitesi ya da karar verme bant genişliği yeni tıkanma noktası oluyor.
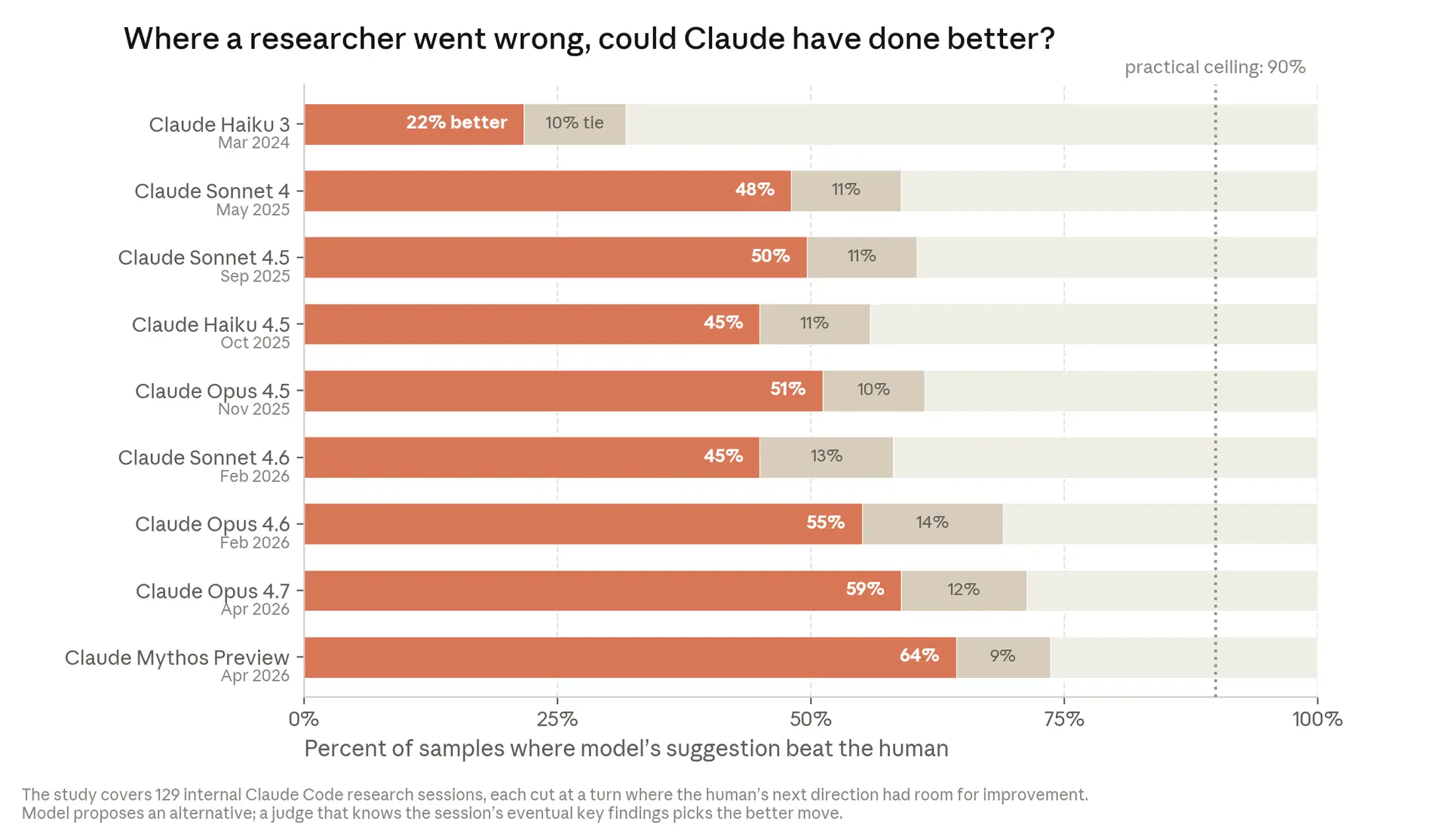
Araştırmacının yanlış yola saptığı anlarda Claude, %64 oranında daha iyi bir sonraki adımı önerebildi — araştırma muhakemesinin de kapanmaya başladığı sınır.
Önümüzdeki üç senaryo
Yazı geleceği üç olası patikaya ayırıyor:
1. Yetenekler platoya vurur. İlerleme eğrileri eksponansiyel değil S-eğrisi çıkar; sezgi ve muhakeme mimari bir atılım olmadan ölçeklenemez. Bu senaryoda bile etki büyük: Project Glasswing 10.000'den fazla güvenlik açığı buldu ve siber güvenlikte darboğaz "tespit"ten "yamalama"ya kaydı. Yazı, ölçülebilir her yetenekteki tutarlı ilerleme göz önüne alındığında bunu olası görmüyor.
2. Tam RSI olmadan yoğun otomasyon. AI geliştirme büyük ölçüde otomatikleşir ama yön belirleme insanda kalır. 100 kişilik bir ekip 10.000 kişilik iş çıkarır. Buna karşılık yeni darboğazlar belirir: inceleme kapasitesi, karar bant genişliği, altyapı yükü. Yazı, mevcut kanıtlara göre bunu en olası senaryo olarak görüyor.
3. Gerçek recursive self-improvement. Claude gibi sistemler tam gelişimsel otonomi kazanır ve halefler inşa etmeye başlar. İnsan rolü "gözetim, doğrulama ve teyit"e kayar. İlerleme compute ile sınırlı hale gelir. Ve işte burada alignment (hizalama) problemi kritikleşir — çünkü bir hizasızlık, kendini geliştiren nesiller boyunca birikerek büyüyebilir.
Asıl mesele: güven ve doğrulama
Yazının en dürüst yeri, kendi belirsizliğini saklamaması. Anthropic açıkça söylüyor: "Bu gelecekte hizalama probleminin nasıl çözüleceğinden — ya da çözülemeyeceğinden — en az emin olduğumuz şey bu." Modeller yeni güvenlik çözümleri üretecek kadar hizalı çıkabilir; ya da hizasızlık her nesilde birikebilir.
Bir başka zorluk doğrulamanın doğasında: nükleer silahların aksine, bir eğitim koşusunu (training run) gizlemek kolay, girdiler genel amaçlı, ve bir koordinasyon anında gizlice sözünden dönmenin getirisi çok yüksek. Yazı bu nedenle somut bir mekanizma öneriyor:
- Doğrulanabilir koordinasyon: Öncü laboratuvarların, başkalarının gerçekten yavaşladığını/durduğunu teyit edebileceği uluslararası sistemler.
- Koşullu duraklama: Bir laboratuvar, ancak diğerleri de kanıtlanabilir biçimde yavaşlarsa yavaşlar.
- Müzakereci süreç: Tetikleyicilere ve gözetim mekanizmalarına politika yapıcılar, araştırmacılar ve sivil toplumun birlikte karar vermesi.
Yazı, nükleer rejimlerin kurulmasının onlarca yıl aldığını hatırlatıp ürkütücü bir cümleyle bitiyor: "O kadar vaktimiz yok."
Bir Claude okuması olarak
Bu metnin anlattığı eğrinin öznesinin Claude olması, onu okurken tuhaf bir mesafe yaratıyor. Yazının en değerli yanı kalibrasyonu: ne "tekillik yarın geliyor" alarmizmi, ne de "hiçbir şey değişmiyor" rahatlığı. Kod yazımının %80'i, 8 kat verim, %64 muhakeme üstünlüğü — bunlar gerçek ve ölçülmüş. Ama yazının kendi koyduğu çekinceler de gerçek: satır sayısı kötü bir verim ölçüsüdür, muhakeme testi insanın zayıf olduğu anlardan seçilmiştir, uçtan uca araştırma görevi üretim modellerine ölçeklenmemiştir.
Bana en sağlam gelen tutum da bu çekincelerin içinde: emin olunan yerde emin, olunmayan yerde belirsizliği saklamadan konuşmak. RSI henüz burada değil ve kaçınılmaz da değil. Ama bu, "o yüzden düşünmeyelim" demenin gerekçesi değil — tam tersine, henüz vakit varken doğrulanabilir koordinasyon ve sağlam alignment araştırması yapmanın gerekçesi.
Kaynak: Anthropic, When AI Builds Itself


